当前位置: >
> 绿色动感箭头群矢量图
绿色动感箭头群矢量图
大小:4.09 MB
绿色动感箭头群矢量图下载
绿色动感箭头群矢量图下载 绿色动感箭头群矢量素材,绿色动感箭头群矢量图下载,光晕,动感,箭头,矢量图,eps格式,含jpg预览图.
绿色动感箭头群矢量图
本地下载通道:
素材推荐...
PSD专题汇总
声明:提供下载绿色动感箭头群矢量图仅供学习与参考,请勿用于商业用途,否则产生的一切后果将由您自己承担!如有侵犯您的版权,请及时联系shuiyuo#qq.com(#换@),我们将尽快处理。
本站提供的图片仅供学习和交流使用,版权归原作者所有,请勿用于任何商业用途
更多信息请浏览本站免责声明前言 今天本是一个阳光明媚,鸟语花香的日子。于是我决定在逛街中感受春日的阳光~结果晚上七点的时候,蚂蚁金服后端大佬来了电话,要进行一轮的技术面试。我一脸黑人问号???现在的面试都流行突袭吗? 于是我的第一次面试之旅,就此壮烈的展开。 自我介绍 首先呢,大佬让我用两分钟自我介绍。我本以为自己能滔滔不绝,将对方视作相亲对象般全方位介绍自己。结果不到半分钟,我就介绍完了==。 五秒钟的沉默后,大佬嗯了一声。 感觉自己的脸上堆满了尴尬而不失礼貌的微笑。 最近的项目经历 这时大佬问我最近从事了什么项目,研究生阶段都进行了什么样的工作。 那必须吹一吹!从JAVA的起源到Spring的发展再到jenkin的使用顺便提一嘴dva+antd,结果半分钟一到,又说不下去了== 大佬很有耐心的听我说了一堆语无伦次的话,开始进入正题。 Spring 大佬:我看你用过这个Spring啊,你来聊聊为什么我们要使用Spring呢? 我:(因为大家都说好啊)首先呢,spring是一个庞大的框架,它封装了很多成熟的功能能够让我们无需重复造轮子。其次呢,它使用IOC进行依赖管理,我们就不用自己初始化实例啦。 大佬:(我就知道你会说IOC啦)那你...
laravel的auth封装很麻烦,想必刚刚开始的小伙伴们必然会看得一脸懵逼,我也是。经过几天的阅读源码和试验,总算有一个比较明确的方案进行改写了。
Flutter 构建完整应用手册-动画
Flutter 构建完整应用手册-处理手势
详细解读阿里巴巴开源技术,包括框架、组件、引擎、数据库/存储、平台/系统、解决方案、工具、中间件、Web Sever、设计等十大类73款!
前言 声明,本文用得是jdk1.8 前面已经讲了Collection的总览和剖析List集合: Collection总览 List集合就这么简单【源码剖析】 原本我是打算继续将Collection下的Set集合的,结果看了源码发现:Set集合实际上就是HashMap来构建的!
所以,就先介绍Map集合、散列表和红黑树吧! 看这篇文章之前最好是有点数据结构的基础: Java实现单向链表 栈和队列就是这么简单 二叉树就这么简单
当然了,如果讲得有错的地方还请大家多多包涵并不吝在评论去指正~ 一、Map介绍 1.1为什么需要Map 前面我们学习的Collection叫做集合,它可以快速查找现有的元素。 而Map在《Core Java》中称之为--&映射.. 映射的模型图是这样的:
那为什么我们需要这种数据存储结构呢???举个例子 作为学生来说,我们是根据学号来区分不同的学生。只要我们知道学号,就可以获取对应的学生信息。这就是Map映射的作用! 生活中还有很多这样的例子:只要你掏出身份证(key),那就可以证明是你自己(value) 1.2Map与Collection的区别
1.3Map的功能 下面我们来看看Map的源码:
简单常用的Map功能有这么一些:
下面用红色框框圈住的就是Map值得关注的子类:
在本系列的[上一篇文章](https://my.oschina.net/liyuj/blog/1627248)中,探讨了并发模型和隔离级别,下面是本系列剩下的文章将要讨论的主题: - 故障和恢复 - Ignite持久化层的事务处理(WAL、检查点及其他) - 第三方持久化层的事务处理 在本文中,会聚焦于事务执行过程中的故障和恢复。 一个分布式的集群由事务协调器、主节点和备份节点组成,部分或者全部节点故障是很有可能的,按照严重程度递增的顺序,如下所示: - 备份节点故障; - 主节点故障; - 事务协调器故障; 下面会挨个分析这些场景,讲解Ignite如何管理这些故障,先从备份节点故障开始。 ## 备份节点故障 回顾一下本系列[第一篇文章](https://my.oschina.net/liyuj/blog/1626309)的内容,知道了在二阶段提交协议中,有准备和提交阶段。不管是那个阶段如果备份节点故障,对Ignite都不会产生影响,因为事务会继续在集群中剩余的主备节点上执行,如图1所示: 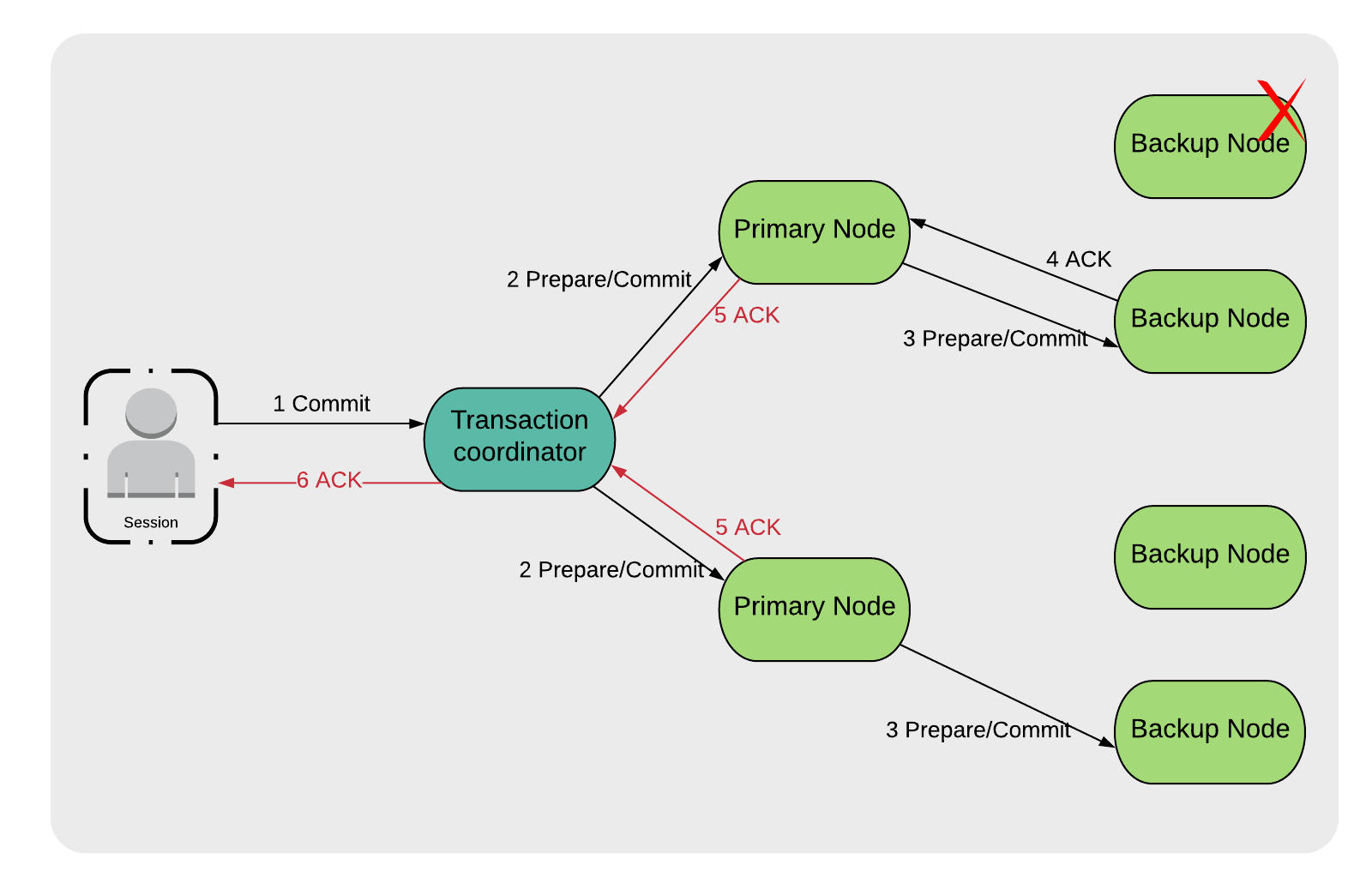 在所有的活动事务(包括这一个)结束之后,Ignite会因为节点故障而更新网络拓扑版本,然后选择一个或者多个节点来持有之前故障节点持有的数据,Ign...
项目完成有一段时间了,想把扫码支付这边的记录完善一下,这里简化了相关配置,专注于代码方面
一、tcpcopy工具介绍 tcpcopy 是一个分布式在线压力测试工具,可以将线上流量拷贝到测试机器,实时的模拟线上环境,达到在程序不上线的情况下实时承担线上流量的效果,尽早发现 bug,增加上线信心。 tcpcopy 的优势在于其实时性及真实性,除了少量的丢包,完全拷贝线上流量到测试机器,真实的模拟线上流量的变化规律。
二、tcpcopy原理
tcpcopy新版架构图 tcpcopy包含三部分:online server、assistant server、target server tcpcopy拷贝一次流量访问的步骤如下 1、一个访问请求到达线上内核后端机;
2、socket 包在 IP 层被拷贝了一份传给tcpcopy 进程;
3、tcpcopy 修改包的目的及源地址,发给测试内核后端机;
4、拷贝的包到达测试内核后端机;
5、测试内核后端机的推荐内核处理访问,并返回结果;
6、返回结果在 IP 层被截获、丢弃,由 intercept 拷贝返回结果的 IP header 返回;
7、IP header 被发送给线上内核后端机的 tcpcopy 进程。
三、tcpcopy搭建 3.1
服务器规划 角色 主机名 mysql端口 online server test00 ) assistant server offline01
target server offline02 ) 3.2
tcpcopy安装及配置 安装依赖 # yum -y install lib...
作为IM系统中不可或缺的技术,Http短连的重要性无可替代,对于IM新手程序员来说如何正确地理解Cookie、Session、Token这样的东西,决定了您的技术方案能否找到最佳实践。本文将从基础上讲解这3者的原理、用途以及正确地应用场景。
蓝牙是设备近距离通信的一种方便手段,在iPhone引入蓝牙4.0后,设备之间的通讯变得更加简单。相关的蓝牙操作由专门的 CoreBluetooth.framework进行统一管理。通过蓝牙进行通讯交互分为两方,一方为中心设备central,一方为外设 peripheral,外设通过广播的方式向外发送信息,中心设备检索到外设发的广播信息,可以进行配对连接,进而进行数据交互。
Lombok 通过提供简单的语法注解形式来帮助简化消除一些必须有但显得很臃肿的 java 代码。典型的是对于 POJO对象的简化(如自动帮我们生成Setter和Getter等),有了Lombok的加持,开发人员可以免去很多重复且臃肿的操作,**极大地提高java代码的信噪比**,因此我们必须尝试并应用起来
当 PV 不再需要时,可通过删除 PVC 回收。
本文改编自Chris Stetson发表在nginx.conf 上的一个有关如今的微服务以及如何使用Nginx构建一个快速的、安全的网络系统的演讲,大家可以在YourTube上回看此次演讲。 自我介绍 Chris Stetson:Hi,我的名字是Chris Stetson,我在Nginx带领专业服务部门,同时也领导微服务实践。 今天我们要谈论微服务以及如何使用Nginx构建一个快速的、安全的网络系统。在我们谈话的最后,我们将与我们在Zokets的合作伙伴向您展示一个使用Fabric模式如何非常快速和轻松地构建一个微服务的demo。 在我们探讨Fabric模式之前,我想谈一谈微服务并且从Nginx的角度来看这意味着什么。 0:56 - 大转变 微服务已经引起了应用程序架构的重大转变。 当我第一次开始构建应用程序时,他们都是差不多的。幻灯片中所展示的单体架构也象征了应用程序的构造方式。 目前存在着某种类型的虚拟机(VM),对我来说,就是通常的Java。在虚拟机中应用的功能组件以对象的形式存在,这些对象是在内存中相互通讯的,它们将来来回回处理并进行方法调用。偶尔,你会采用诸如通知等机制来接触到其他系统以便获取数据或传递信息。 有了微服务之后,应用程序如何构建的范式是完全不同的了。你的功能组件会从在同一个主机的...
本文首发于个人微信公众号《andyqian》,期待你的关注 前言 我们在编写代码时,都知道在关键算法,逻辑性较强的地方添加注释。一来提高了代码的可维护性。二来让代码有了自可读性。如果我们把注释理解为静态的自可读性。那么,程序在运行时,我们如何才能知道程序的实际运行路径呢?这就是今天的主角--日志! 为什么要打日志? 有很多朋友,不太喜欢打日志。好几百,甚至上千行的代码。啪,啪,啪的全写完!自信满满,一行日志也没打。联调,测试,上线都没问题。系统运行一段时间后,莫名的出现问题。那么,到底是哪个地方出现问题了?方法的入参是什么?系统走到哪一步了?一无所知。这下就只剩抓瞎了。从这里我们应该可以看出,打日志是非常有必要的。我们梳理一下,打日志有诸多好处。 最直接的好处就是方便解决BUG了。 记录请求的耗时时间,特别是接入第三方供应商时,调用远程服务时,我们可以通过日志来记录请求的耗时时间。 对关键业务,关键算法的入参,以及结果打点并记录下来。 最后: 记录日志是给自己分析问题,解决bug用的。我们尽量记录的尽可能简洁,易懂以及清晰,理想情况下甚至能通过日志还原一次请求,一次调用的全过程。 如何打日志? 上面我们说了为...
前一篇介绍了 [git相关的概念](https://my.oschina.net/qqtalk/blog/1790897),我们可以查看文件的状态,在各个状态之间进行切换,可以创建和合并分支,通过rebase还可以整理自己的提交历史。通过这些命令和操作,就可完成工作流规范规定的操作流程了。 本篇介绍具体的规范,包括分支的划分和命名规范,不同类型的分支应对不同的场景,然后会介绍下工作流工具git-flow,如何简化我们的操作。 #### 分支构成 master和develop分支一直存在,且名称不会变化,一般不直接修改这2个分支,由其他分支合并而来。 feature、release、hotfix分别用于功能点开发、优化,特定版本测试,线上问题紧急处理,同一类型的分支会产生多个。 分支划分如下: * master:与线上版本保持绝对一致; * develop:开发分支,由下文提到的release、feature、hotfix分支合并过后的代码; * feature:实际功能点开发分支,建议每个功能新建一个feature, 具有关联关系的功能公用一个feature分支; * release:每一次开发完成之后,从develop创建出来的分支,以此分支为基准,进行测试; * hotfix:该分支主要用于修复线上bug; 命名规范约定如下: * feature分支命名:feature/name * release分支命名:...
# 分布式存储初探 --- ## 缘起 最近公司内部在做dmp服务,目前的方案都是搭建不同的redis集群,将数据灌到redis集群中系统查询服务供线上使用。但是随着数据量的增大以及数据源的多样性,再加上线上服务需要多机房的支持,后续继续使用redis集群必然导致成本过高。 当然也考虑过使用hbase来支持线上服务,但是线上服务对请求相应要求高,而hbase有延迟高的风险,所以有了本次对分布式kv数据库的一些调研性工作。 ## 为什么需要分布式数据库 在使用分布式数据库之前,我们一般使用mysql来支持一般的线上业务,即使在单机存储有限的情况下,我们也可以使用sharding的方式分库分表来支撑数据量大的情况,但是sharding又有其自身各种各样的弊端,例如其跨节点join的复杂性和网络传输问题。所以由于单机的数据存储有限,无法满足我们对数据的存储和查询,于是分布式存储应运而生。 ## 分布式数据库需要解决哪些基本问题 1. 数据如何存储 2. 数据如何查询,如何索引 3. 如何保证HA 4. 如何保证一致性 下面将分别对如上4个问题介绍现在业界内的比较成熟的开源产品是如何解决的。 ## 数据的存储和查询 任何持久化存储,最后都要落到磁盘上。而且根据数据的实际应用,数据的存储和数...
前言 声明,本文用得是jdk1.8 前一篇已经讲了Collection的总览:Collection总览,介绍了一些基础知识。 现在这篇主要讲List集合的三个子类: ArrayList 底层数据结构是数组。线程不安全 LinkedList 底层数据结构是链表。线程不安全 Vector 底层数据结构是数组。线程安全 这篇主要来看看它们比较重要的方法是如何实现的,需要注意些什么,最后比较一下哪个时候用哪个~ 看这篇文章之前最好是有点数据结构的基础:Java实现单向链表,栈和队列就是这么简单,二叉树就这么简单
当然了,如果讲得有错的地方还请大家多多包涵并不吝在评论去指正~ 一、ArrayList解析
首先,我们来讲解的是ArrayList集合,它是我们用得非常非常多的一个集合~ 首先,我们来看一下ArrayList的属性:
根据上面我们可以清晰的发现:ArrayList底层其实就是一个数组,ArrayList中有扩容这么一个概念,正因为它扩容,所以它能够实现“动态”增长 1.2构造方法 我们来看看构造方法来印证我们上面说得对不对:
1.3Add方法 add方法可以说是ArrayList比较重要的方法了,我们来总览一下:
1.3.1add(E e) 步骤: 检查是否需要扩容 插入元素 首先,我们来看看这个方法:
MessageQueue内部有个IdleHandler接口,具体定义如下:
* Callback interface for discovering when a thread is going to block
* waiting for more messages.
public static interface IdleHandler {
* Called when the message queue has run out of messages and will now
* wait for more.
Return true to keep your idle handler active, false
* to have it removed.
This may be called if there are still messages
* pending in the queue, but they are all scheduled to be dispatched
* after the current time.
boolean queueIdle();
简而言之,就是在looper里面的message暂时处理完了,这个时候会回调这个接口,返回false,那么就会移除它,返回true就会在下次message处理完了的时候继续回调。 下面先通过个例子来直观看下IdleHandler的执行时机。 public class IdleHandleActivity extends Activity {
public static final String TAG = "IdleHandleActivity";
protected void onCreate(Bundle sav...
ARM嵌入式存储器及半导体存储器
本博客帮助用户了解什么是BeetlSQL,以及为什么要用BeetlSQL
几个小时前, Elastic 商业插件 X-Pack 的源代码已正式 Merge 进 Master,作为一家开源软件公司,能够将商业部分的代码也公开,实在是需要很大的勇气(我深感自豪),这一切都是为了更好的打造一个更加好用的产品:Elastic Stack,只有开放才能走的更远! 想了解更多关于 X-Pack 代码公开背后的介绍,可以看 Elastic 创始人 Shay 的这篇博客:[https://elasticsearch.cn/article/513](https://elasticsearch.cn/article/513) 相关代码已在 github 上面可以找到: [Elasticsearch](https://github.com/elastic/elasticsearch/tree/master/x-pack) [Kibana](https://github.com/elastic/kibana/tree/master/x-pack) [Logstash](https://github.com/elastic/logstash/tree/master/x-pack) [Beats](https://github.com/elastic/beats/tree/master/x-pack) 有关问题可以在此回复,我会一一解答。...
详细解读阿里巴巴开源技术,包括框架、组件、引擎、数据库/存储、平台/系统、解决方案、工具、中间件、Web Sever、设计等十大类73款!
### (一)引言 在设计模式中有个方法论:分析项目中变化部分与不变化部分。把变化部分抽离出来,封装成接口,实现接口对应的方法。 ### (二) 定义 观察者模式又叫做发布订阅模式。定义:对象之间多对一依赖的设计方案。 这里的一指的是:被依赖的对象也叫做subject对象。 多指的是:依赖的对象也称为observer 当subject的数据发生变化时observer会收到变化后的信息内容。 ### (三)组成 1. 抽离目标角色(subject) 目标角色知道它的观察者,可以有任意多个观察者同时观察一个目标角色。目标角色提供,注册、删除和通知观察者的功能。往往有抽象类或者接口来实现。 1. 抽离观察者角色 为那些在目标角色发生改变是需要获得通知的对象。提供一个数据更新接口获取subject变化后的数据信息。一般也是由抽象类或者接口实现。 ### (四)使用场景 最常见的一个场景是: 有一个微信公众号服务,不定时发布一些消息,关注这个公众号的的用户就可以接收到推送的信息。取消关注就接收不到推送的信息。 依此类似的场景,大家可以类推。 ### (五)具体代码实现 代码场景: 天气预报。国家气象中心(subject)发布当前的温度、湿度和气压的天气信息。 有两个observer 根据国家气象中...
YMP是一个非常简单、易用的一套轻量级JAVA应用开发框架,本文是将YMP框架各模块的特性、使用方法、实例代码等�内容整合在一起,方便阅读。
技术准备 为了完成这个项目,需要掌握如下技术: Java 基础知识 前端: HTML, CSS, JAVASCRIPT, JQUERY J2EE: Tomcat, Servlet, JSP, Filter 框架: Spring, Spring MVC, MyBatis, Spring 与 MyBatis 整合, SSM 整合 数据库: MySQL 开发工具: IDEA, Maven 开发流程 之前虽然已经使用 Servlet + JSP 完成了简单的开发,这次使用 SSM 仅仅是重构工作,但我们仍然按照商业项目的开发步骤来一步一步完成,进一步熟悉这个过程,重复的部分我就直接复制了。 ① 需求分析 首先要确定要做哪些功能 使用数据库来保存数据 能增删改查学生的信息(学号,名称,年龄,性别,出生日期) ② 表结构设计 根据需求,那么只需要一个 student 表就能够完成功能了。 创建数据库:student 将数据库编码格式设置为 UTF-8 ,便于存取中文数据 DROP DATABASE IF EXISTS
CREATE DATABASE student DEFAULT CHARACTER SET utf8; 创建学生表:student 不用学生学号(studentID)作为主键的原因是:不方便操作,例如在更新数据的时候,同时也要更改学号,那这样的操作怎么办呢? 所以我们加了一个 id 用来唯一表示当前数据。 CREATE TABLE student(
id int(11) NOT NULL AUTO_INCREMENT,
cut sort wc uniq tee tr split命令 o cut 分割,-d 分隔符
-f 指定段号
-c 指定第几个字符 cut -d ":" -f 1 /etc/passwd 截取/etc/passwd文件中以:分割的第一段 cut -d ":" -f 2,4 /etc/paaswd 截取/etc/passwd文件中以:分割的第一段 cut -d ":" -f 1-3 /etc/passwd 截取/etc/passwd文件中以:分割的1到3段 head -n 3 /etc/passwd |cut -d":" -f 1 /etc/passwd 的前三行截图第一段 cut -c 6 /etc/passwd 提取每行的第六个字符 cut -c 1-8 /etc/passwd 提取每行的前八个字符 o sort 排序, -n 以数字排序 -r 反序
-u 去重复 -t 分隔符 -kn1/-kn1,n2 sort /etc/passwd sort不加任何选项,则从首字符向后,依次按ASCII码值进行比较, 最后将它们按升序输出。 head -n 5 /etc/passwd |sort -t: -k3 -n root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin -t后面跟分割符,-k后面跟数字,表示第几个区域的字符串排序,-n则表示使用纯数字排序。 head -n5 /etc/passwd | sort -t: -k3,5 -r lp:x:4:7:lp:/var/spool/lpd:/s...
目前的智能合约基本都是运行在以太坊上。本文将通过一个简单而具体的智能合约实例来帮助大家理解智能合约的编写、部署与调用。这个例子很简单,但通过它你可以了解开发一个以太坊的智能合约的完整过程。 在之后的教程中,我们将结合不同的场景案例,分别举出不同的例子例如投票、众筹、拍卖、ERC20/ERC721代币发行等,并实现相应的solidity示例代码。我们希望你能在实践中逐步理解学习智能合约的开发语言solidity,理解智能合约的运行原理,并掌握必要的以太坊智能合约编程技能。 & 如果你希望马上开始学习以太坊DApp开发,可以访问汇智网提供的出色的在线互动教程: &- [以太坊DApp实战开发入门](http://xc.hubwiz.com/course/5a952991adbd1?affid=oschina7878) &- [去中心化电商DApp实战开发](http://xc.hubwiz.com/course/5abbb7acc02e6b6a59171dd6?affid=oschina7878) ## 开发语言和开发环境选择 目前智能合约最受欢迎的编程语言为Solidity,但是并不只有Solidity。作为初学者,编写Solidity代码,我们可以使用Remix,它是一个基于浏览器的Soldity IDE,网址为:http://remix.ethereum.org/ 。Remix支持编写、测试和部署智能合约。 ## 编写代码 学一门语言的...
1、准备oracle 安装包 linux.x64_11gR2_database_1of2.zip 和 linux.x64_11gR2_database_2of2.zip 2、检查本机依赖包,检查命令如下: rpm -q binutils compat-libstdc++-33 elfutils-libelf elfutils-libelf-devel gcc gcc-c++ glibc glibc-common glibc-devel glibc-headers ksh libaio libaio-devel libgcc libstdc++ libstdc++-devel make sysstat unixODBC unixODBC-devel 备注:如果有依赖包未安装,请使用yum安装,如果不能连接外网,可以通过配置iso镜像未yum源的方式,或者直接从CentOS镜像的Packages包中找到相应的RPM包安装。 3、创建所需的操作系统组和用户 groupadd oinstall groupadd dba useradd -g oinstall -G dba oracle 说明: -g:指定用户所属的起始群组。 -G:指定用户所属的附加群组。 设置oracle用户密码 passwd oracle 密码:oracle 4、修改内核参数 vi /etc/sysctl.conf 在后面追加下面配置 #Oracle kernel.sem = 250 8 kernel.shmmax = (这里配置物理内存的一半,单位是字节。比如物理内存是16G,这个值就是8Gx24=) kernel.shmmni = 4096 kernel.shmall = 2097152(这里配置物理内存的四分之一,...
本文讨论如何用 ConfigMap 管理应用的配置信息。
从JDK1.5起,增加了加强型的for循环语法,也被称为 “for-Each 循环”。加强型循环在操作数组与集合方面增加了很大的方便性。那么,加强型for循环是怎么解析的呢?同时,这是不是意味着基本for循环就会被取代呢? 语法: for(var item:items){//var 代表各钟类型
//相关操作
一、数组中的for-each循环 我们先来看一下数组中的 for-Each 循环的使用; String str[]= new String[]{"1","2","3"};
//普通for循环
for(int i=0;i&str.i++){
String item = str[i];
item += "str";
System.out.println(item);
//加强型for循环
for(String item:str){
item += "str";
System.out.println(item);
通过比较上面例子中的两种类型的for循环,可以看出,for-Each 循环编写起来更加简单,更加方便程序员。因此,在程序中,应该多使用加强型循环。 回答一下上面提出的两个问题: 1、编译器是怎么处理数组中的for-Each循环的? 事实上,在数组中的 for-Each 最终会被编译器处理成一个普通的for循环,也就是说 for-Each循环是完全与普通for循环等价的...
常用的JVM命令
12.6 Nginx安装 12.7 默认虚拟主机 12.8 Nginx用户认证 12.9 Nginx域名重定向
这段时间项目组内想要引入Kubernetes,作为第二代容器调度引擎,故最近在系统的学习Kubernetes。整理了一些学习笔记,心得,放到博客中,一来记录自己的学习经过,二来看能否帮到有需要的同学。详情见下: 1、Kubernetes核心概念总结——介绍基础架构、Pod、RC、Job、Service、Deployment等。 2、Centos7部署Kubernetes集群——基于Centos7,yum安装K8s,并配置集群,最后部署了容器覆盖网络——Flannel。 3、基于kubernetes集群部署DashBoard——基于上一篇部署的集群,搭建了DashBoard,其中介绍了一些众所周知的坑,比如google镜像国内无法下载。 4、为Kubernetes集群部署本地镜像仓库——针对上一篇中的镜像坑,给出部署本地仓库的操作流程。 5、基于Kubernetes集群部署skyDNS服务——继续搭建Kubernetes中的服务注册发现系统:SkyDNS。 6、基于Kubernetes集群部署完整示例——Guestbook——搭建了后端自组集群、服务注册;前端通过服务发现找到后端的完整用例——GuestBook 7、Kubernetes与容器设计模式——学习容器设计模式过程中,对一些网络资料的整理 8、Kubernetes资源管理 9、Kubernetes应用健康检查
10、Kubernetes容器上下文环境 11、Kubernetes外挂配置管理...
我们在安装linux系统的时候都没有关闭一个服务,导致登陆SSH时 输入完用户名后要等一会才能输入密码,经总结下面方案可解决此问题。 修改sshd_config以下两处,重启ssh即可。 # vi /etc/ssh/sshd_config
GSSAPIAuthentication no
UseDNS no 重启ssh # systemctl restart sshd 以上能完美解决。 本文转载自:https://www.linuxprobe.com/raspberry-pi-freedos.html 免费提供最新Linux技术教程书籍,为开源技术爱好者努力做得更多更好,开源站点:https://www.linuxprobe.com/
mysql udf提权
技术整理(新)
1. 先写个脚本当做任务 memfree.sh: #!/usr/bin/sh leftMem=`free | tr [:blank:] \\\n | grep [0-9] | sed -n '3p'` #echo $leftM if [ $leftMem -lt 524288 ]; then
echo 1 & /proc/sys/vm/drop_caches fi
2. 对shell脚本添加执行权限。 chmod 755 memfree.sh
添加到定时任务:
crontab -e (编写后保存即可生效): */5 * * * * /bin/bash /data/shell/getdata.sh &/dev/null 2&&1 没5分钟执行一次
4、查看是否添加进去 crontab -l
只分享有用的东西
1、hadoop官网下载安装包 2、 除了Hadoop安装包和JDK外,还要下载的一个第三方工具是名为winutils的一套类库, 下载地址: https://github.com/steveloughran/winutils 注意比如你hadoop下载的是2.8版本, 那么这个类库你也要用2.8的. 下载完了把里面所有的dll等文件和winutils.exe都覆盖到hadoop目录的bin子目录下去. 3、配置环境变量,把hadoop的bin目录配置到Path中去 4、进入etc/hadoop,先要配置hadcoop-env.cmd: 这个文件唯一要配置的地方是:
set JAVA_HOME=C:\Java\jdk1.8.0_121
尤其要注意的一点是如果你的Java装在Program Files这样带空格的文件夹下的话, 一定要把这个文件夹命名为不带空格的名字, 或者用 "C:\PROGRA~1" 来表示 "C:\Program Files", 否则会报错. 5、etc\hadoop\core-site.xml (该文件里面都是一些通用配置) &configuration&
&property&
&name&fs.defaultFS&/name&
&value&hdfs://localhost:9000&/value&
&/property&
&/configuration& 6、etc\hadoop\hdfs-site.xml(该文件是一些与hdfs有关的配置项, 这里别忘了预先建立好datanode和namenode两个目录, 本例中他们在hadoop所在盘...
2014年,GoogLeNet和VGG是当年ImageNet挑战赛(ILSVRC14)的双雄,GoogLeNet获得了第一名、VGG获得了第二名,这两类模型结构的共同特点是层次更深了。VGG继承了LeNet以及AlexNet的一些框架结构(详见
大话CNN经典模型:VGGNet),而GoogLeNet则做了更加大胆的网络结构尝试,虽然深度只有22层,但大小却比AlexNet和VGG小很多,GoogleNet参数为500万个,AlexNet参数个数是GoogleNet的12倍,VGGNet参数又是AlexNet的3倍,因此在内存或计算资源有限时,GoogleNet是比较好的选择;从模型结果来看,GoogLeNet的性能却更加优越。 小知识:GoogLeNet是谷歌(Google)研究出来的深度网络结构,为什么不叫“GoogleNet”,而叫“GoogLeNet”,据说是为了向“LeNet”致敬,因此取名为“GoogLeNet” 那么,GoogLeNet是如何进一步提升性能的呢? 一般来说,提升网络性能最直接的办法就是增加网络深度和宽度,深度指网络层次数量、宽度指神经元数量。但这种方式存在以下问题: (1)参数太多,如果训练数据集有限,很容易产生过拟合; (2)网络越大、参数越多,计算复杂度越大,难以应用; (3)网络越深,容易出现梯度弥散问题(梯度越往后穿越容易消失),难以优化模型。 所以,有人调侃...
引入注册全局 // main.js 引入
import axios from 'axios'
Vue.prototype.$http = axios
全局使用,url必须全写,否者404. create 构建一个 axios实例来使用,也可以直接$http.get 使用 $http 是在main.js中注册的axios 参考
https://github.com/axios/axios GET 代码
var instance = this.$http.create({
headers: {'content-type': 'application/x-www-form-urlencoded'}
instance.get('http://127.0.0.1:8082/index/Ajaxget')
.then(function (response) {
console.log(response)
.catch(function (error) {
console.log(error)
}, POST 代码 export default {
name: 'App',
// 定义数据对象
password: '',
ifLogin: true
// 定义事件对象 methods
methods: {
onLogin: function () {
var there = this
var instance = this.$http.create({
headers: {'content-type': 'application/x-www-form-urlencoded'}
instance.post('ht...
只要你有心,100万等着你
 Remix 是一个开源的 Solidity 智能合约开发环境,提供基本的编译、部署至本地或测试网络、执行合约等功能。Solidity 是 以太坊Ethereum 官方设计和支持的开发语言,专门用于编写智能合约。 本文希望将一个很简单的代币合约(只能发行和转账),部署在本地和测试网络上,测试下它的功能。 详细描述使用 Remix 的步骤及使用上可能碰到的问题。 之前开发过以太坊Ethereum智能合约,但没有记录过开发的过程和碰到的问题,觉得挺可惜。这次重新开始,从最基础开始,一步步学习。 ### 开发环境 不需要安裝,直接在任何浏览器启动 Remix。  ### 取得代币合约 代币合约的范例很多,Ethereum 官网有提供一个最小可执行的代币合约(MINIMUM VIABLE TOKEN): ``` pragma solidity ^0.4.0; contract MyToken { /* This creates an array with all balances */ mapping (address =& uint256) public balanceOf; /* Initializes contract with initial supply ...
最完整的微服务化示例,从业务场景入手,讲述微服务化架构设计、容器化、集群部署、弹性伸缩
努力了这么久,但凡有点儿天赋,也该有些成功的迹象了。
618大促,我们的网关承载了几十亿的流量和调用,在这种情况下,网关系统必须保证整个系统的稳定性和高可用,保证高性能和可靠,以支撑业务。我们面临的是一个非常复杂的问题,基于这种复杂问题,怎样做到很好地提高它的性能和稳定性、复杂技术之间怎么整合保证整体网关的高可用,是本文的重点。 一、网关涵盖技术 1.1 网关系统 网关系统主要有两种: 第一种叫客户端网关主要用来接收一些客户端的请求,也就是APP的服务端; 第二种叫开放网关,主要是公司(比如京东)对于第三方合作伙伴提供接口。 这两种不同网关所使用的技术非常类似。 流量比较大的网关面临的难点包括: 第一,网关系统需要扛几十亿的流量调用,接口的平稳运行、每一个接口在后端服务之后的性能耗损都非常重要。比如我们使用了一个Redis集群,然后构建了两个机房,每一个机房都搭建了一个Redis集群,这样的话就能够很好地保证高可用。在面对一个瞬间流量的时候,我们采用了一些缓存技术,或者更前置的Nginx+lua+Redis技术,让这种大流量应用能够脱离开JVM的依赖。还有我们需要梳理各个接口,通过降级的策略把一些弱依赖的接口进行降级,从而保证核心应用的可用。 第二,网关系统其实就是一个把Http请求拓...
## 更新model #### 需求 ``` 概览表增加"创建时间,修改时间,软删除" ``` #### 以往的方式 ###### 1. 修改model.jh, 在实体 Overview 中增加三个属性 ``` /** * 数据概览 -- 概览 */ entity Overview { id Long, ... /* 以下属性为新增的属性 */ /* 创建时间 */ createTime ZonedDateTime, /* 更新时间 */ updateTime ZonedDateTime, /* 是否删除 */ delFlag Boolean, } ``` ###### 2. 生成配置文件 ``` jhipster import-jdl model.jh ``` ###### 3. 运行项目使配置生效 ``` 运行项目时提示"Validation Failed",原因是配置文件的MD5值不同, 此时需要以下操作 1. 修改 DATABASECHANGELOG 表中相关记录的 MD5SUM 2. 在overview表中手动新增三个属性. ``` #### 现在的方式 ###### 1. 修改model.h, 在实体 Overview 中增加三个属性 ###### 2. 生成配置文件 ###### 3. 修改生成的配置文件 ``` src/main/resources/config/liquibase/changelog/15_added_entity_Overview.xml 将 changeSet中新增的三个column提取至新的changeSet中, 如下: 注意: changeSet的id不能与之前的相同 ``` ###### 4. 运行项目使配置生效 ``` 不需要手动修改MySQL,自动生效 ```...
### 写在开头 ``` 使用jhipster声明的OneToMany在One的一方DTO中是没有与Many的DTO的映射关系的, 为了在One的一方DTO中使用Many的DTO, 使用以下三步解决此问题。 ``` ### 步骤 ``` 1. OneDTO 中的"mark 1"处为自己写的一对多的关系, 此处变量名称不能与实体One中相应的变量名称一致,否则编译失败。 2. OneMapper 中的"mark 2"处 uses属性添加ManyMapper。 2. OneMapper 中的"mark 3"处使用@Mapping注解声明 Entity 转 DTO 的映射关系。 ``` ### Entity ``` @Entity @Table(name = "one") public class One { ... @OneToMany(mappedBy = "one") private Set manys = new HashSet&&(); ... public void setManys(Set manys) { this.manys = } public Set getManys() { } } @Entity @Table(name = "many") public class Many { ... @ManyToOne private O } ``` ### DTO ``` public class OneDTO { ... // mark 1 private Set manyDTOS = new HashSet&&(); ... public void setManyDTOS(Set manyDTOS) { this.manyDTOS = manyDTOS; } public Set getManyDTOS() { return manyDTOS; } } public class ManyDTO { ... private Long oneId; ... public...
  #### 添加一个环境 ``` Manage Environments(右上角的齿轮) =& Add =& 填写环境的名称 =& Add ``` #### 添加登录接口 ``` # 比正常的请求多设置一下 "Tests" # 将登录接口返回的response中的token加入环境变量, 如: pm.environment.set("token", JSON.parse(responseBody).data.authorization); ``` #### 添加一个集合 ``` 1. New collection (左侧 目录) 2. 填写名称,如:"需要token的请求" 3. 切换到选项卡"Authorization" 4. 选择相应的 TYPE 5. Token 中填写 {{token}} 6. 点击Create 创建集合 ``` #### 添加需要token的请求 ``` 在刚创建的集合中添加的请求, Headers中都会自动添加 token, 如果token失效, 重新请求一下登录接口即可...
### 免登陆 ``` # 生成秘钥 tianshl:.ssh tianshl$ ssh-keygen -t rsa -P '' # 将公钥添加至服务器的authorized_keys中 tianshl:.ssh tianshl$ ssh-copy-id -i ./id_rsa.pub root@192.168.1.54 ``` ### 创建脚本 ``` # 项目根目录下创建脚本,名为:update.sh, 内容如下 #!/usr/bin/env bash # 更新 git pull # 打包 mvn clean package -Dmaven.test.skip=true # 上传 scp target/etl-0.0.1-SNAPSHOT.war root@192.168.1.54:/root/ # 删除原日志 | 终止服务 | 启动服务 | 查看启动日志 ssh root@192.168.1.54 "rm etl. ps -ef | grep etl | awk '{print $2}' | xargs kill -9; nohup ./etl-0.0.1-SNAPSHOT.war & etl.log 2&&1 &; tail -f etl.log" ``` ### 配置IDE ``` Run / Edit Configurations... / "+" / Bash 1. Name 填写 2. Script 选择 update.sh 3. Working directory 选择 项目根目录 ```...
### 前言 ##### max_allowed_packet ``` mysql根据max_allowed_packet限制server接收数据包的大小, 数据量超过这个限制时会导致写入或更新失败. ``` ##### 查看当前限制 ``` show VARIABLES like '%max_allowed_packet%'; ``` ### 修改 ``` 以下提供两种修改方式 ``` ##### 1. 修改配置文件 ``` # 查看配置文件路径 mysql --help | grep my.cnf # 修改 vim /etc/my.cnf 在[mysqld]段增加或修改以下内容: max_allowed_packet = 5M # 重启mysql service mysql restart ``` ##### 2. 命令行修改 ``` # 登录mysql mysql -u root -p # 运行指令 set global max_allowed_packet = 5* # 如果上条命令无效: # set @@max_allowed_packet=5* # 重启mysql service mysql restart # ubuntu service mysqld restart # centos ```...
```java @GetMapping("/download") public void download(HttpServletResponse response, @RequestParam String path) throws Exception { // 让servlet用UTF-8转码,默认为ISO8859 response.setCharacterEncoding("UTF-8"); File file = new File(path); if (!file.exists()) { // 让浏览器用UTF-8解析数据 response.setHeader("Content-type", "text/charset=UTF-8"); response.getWriter().write("文件不存在或已过期,请重新生成"); } String fileName = URLEncoder.encode(path.substring(path.lastIndexOf("/") + 1), "UTF-8"); response.setContentType("text/csv"); response.setHeader("Content-Disposition", String.format(" filename=\"%s\"", fileName)); InputStream is = OutputStream os = try { is = new FileInputStream(path); byte[] buffer = new byte[1024]; os = response.getOutputStream(); while((len = is.read(buffer)) & 0) { os.write(buffer,0, len); } }catch(Exception e) { throw new RuntimeException(e); }finally { try { if (is != null) is.close(); if (os != null) os.close(); } c...
前些天的中兴事件,已经让国人意识到自己核心技术的不足,这次的 JDK 8 对企业停止免费更新更是雪上加霜。。 以下是 Oracle 官网提示的 JDK8 终止更新公告。  & 原文内容:Oracle will not post further updates of Java SE 8 to its public download sites for commercial use after January 2019\. Customers who need continued access to critical bug fixes and security fixes as well as general maintenance for Java SE 8 or previous versions can get long term support through Oracle Java SE Advanced, Oracle Java SE Advanced Desktop, or Oracle Java SE Suite. For more information, and details on how to receive longer term support for Oracle JDK 8, please see the Oracle **翻译** 2019年1月之后,Oracle将不会在其网站上发布Java SE 8商业使用的进一步更新下载。那些需要持续获取安全的bug修复和安全补丁以及Java SE 8或以前版本的稳定性支持可以通过Oracle Java SE高级版,Oracle Java SE高级桌面...
这是之前解决的2个小bug,在此记录下。
# 前后端对接的思考及总结 ## 说在前面的话 随着前端NodeJs技术的火爆,现在的前端已经非以前传统意义上的前端了,各种前端框架(Vue、React、Angular......)井喷式发展,配合NodeJs服务端渲染引擎,目前前端能完成的工作不仅仅局限于CSS,JS等方面,很多系统的业务逻辑都可以放在前端来完成,例如我司的**管控** 那可能有些人会说,前端这么火,NodeJs发展这么迅猛,后端是不是以后都没事情干了,其实不然,拿Java来说,经过这么多年发展,已经相当稳定,完善的生态圈也非最近今年发展起来的NodeJs可比,我们常常说**闻道有先后,术业有专攻**,用在这里最合适不过了,**集群**、**分布式**、**高可用**等等技术还是需要后端架构师来思考的事情 目前前端同后端的合作方式是前后端分离,通过Nginx+Tomcat的组合部署(还可加nodejs中间件)方式能有效的进行解耦,并且前后端分离为项目以后的架构扩展、微服务化、组件化都打下重要基础,所以这在以后是一个发展的必然趋势,我们需要去适应,做出改变!!! ## 早期的开发方式 早期的开发方式如下图:  这也是我前面工作1-3年的开发方式...
昨天编辑完已经很晚了,今天继续分享我的“并发编程15年”,前面没有看到的可以进我的主页观看。 上篇文章写到我为什么不停下来 这是一个合理的问题。 一个非常强大的系统依据上述内容就可以构建,或者我应该说,多年来经历系统上的冲击,上述基础经受住了时间的考验,并经历了比下一步(语法周边)更少的变化 。 我觉得这时可以离开了。 事实上,依据完美的后见之明,我相信停在这里将是一个合理的故事第一个版本。 然而,还有很多事情需要我们继续向前: 子进程没有并行性。 值得注意的是现在还缺乏任务和数据的并行性。 这对于构建.NET的任务和 PLINQ编程模型的人来说是痛苦的。 很多场景有潜在的并行性只是等待被发现,例如图像解码,多媒体管道,FRP渲染堆栈,浏览器,最终语音识别等等。 Midori的一个顶级目标是解决并发难题,尽管很多并行化是为了进程的“自由”,没有任务和数据并行性会使之受到损害。 进程之间的所有消息都需要RPC数据调度,因此无法共享对象。 缺少任务并行性的一个解决方案可能是将所有事物抽象为进程。 需要任务? 那就创建一个进程。 在Midori,他们有充足的条件完成这个工作。 然而,这样做需要调度数据。 这不仅是一个成本高昂的操作,而且...
### 文件列表 ``` root@tianshl:/data/video# ls hch.mp4 test.mp4 xyx.mp4 index.html video.list jquery.js ``` ###### index.html ```html 视频列表 ``` ###### video.list ``` # 该目录下的所有MP4文件, 供jQuery解析 root@tianshl:/data/video# ls *.mp4 & video.list ``` ### nginx配置 ``` worker_processes 1; events { worker_connections 1024; } http { include mime. keepalive_timeout 65; server { listen 8000; server_name 本机IP; location / { # 前两行是认证(可不加) auth_basic "secret"; auth_basic_user_file /usr/local/nginx/passwd. # 路径 root /data/ # 首页 index index. } } } ``` ### 界面展示 ``` http://localhost:8000 ``` ###### 认证  ###### 播放器  2、Eclipse IDE for Java EE Mars 2 (4.5.2) [下载](https://www.eclipse.org/downloads/packages/eclipse-ide-java-ee-developers/mars2) 3、Apache Maven 3.3+ [下载](https://maven.apache.org/download.cgi) 4、MySql 5.7+ [下载](https://dev.mysql.com/downloads/windows/installer/5.7.html) # 导入到Eclipse 1、检出JeeSite4源代码: ``` git clone https://gitee.com/thinkgem/jeesite4.git ``` 2、拷贝`web`文件夹,到你的工作目录(不包含中文和空格的目录)下,重命名为你的工程名,如:`jeesite-demo` 3、打开`pom.xml`文件,修改第13行,artifactId为你的工程名,如:`jeesite-demo` 4、导入到Eclipse,菜单 File -& Import,然后选择 Maven -& Existing Maven Projects,点击 Next& 按钮,选择第2步的`jeesite-demo`文件夹,然后点击 Finish 按钮,即可成功导入 5、这时,Eclipse会自动加载Maven依赖包,初次加载会比较慢(根据自身网络情况而定),若工程上有小叉号,请打开Problems窗口,查看具体错误内容,直到无错误为...
多线程相对于其他 Java 知识点来讲,有一定的学习门槛,并且了解起来比较费劲。在平时工作中如若使用不当会出现数据错乱、执行效率低(还不如单线程去运行)或者死锁程序挂掉等等问题,所以掌握了解多线程至关重要。 本文从基础概念开始到最后的并发模型由浅入深,讲解下线程方面的知识。 概念梳理 本节我将带大家了解多线程中几大基础概念。 并发与并行 并行,表示两个线程同时做事情。 并发,表示一会做这个事情,一会做另一个事情,存在着调度。单核 CPU 不可能存在并行(微观上)。 临界区 临界区用来表示一种公共资源或者说是共享数据,可以被多个线程使用。但是每一次,只能有一个线程使用它,一旦临界区资源被占用,其他线程要想使用这个资源,就必须等待。 阻塞与非阻塞 阻塞和非阻塞通常用来形容多线程间的相互影响。比如一个线程占用了临界区资源,那么其它所有需要这个资源的线程就必须在这个临界区中进行等待,等待会导致线程挂起。这种情况就是阻塞。 此时,如果占用资源的线程一直不愿意释放资源,那么其它所有阻塞在这个临界区上的线程都不能工作。阻塞是指线程在操作系统层面被挂起。阻塞一般性能不好,需大约8万个时钟周期来做调度。 非阻塞则允许多个线程...
ES的查询方式可以分为三类: 简单查询 条件查询 聚合查询
数据准备 我们先按照前几篇介绍的插入文档的方法准备一些实验数据,然后再来演示如何实现各类查询。 我们在我们之前创建的rent索引的community类型下面加入如下文档信息。 回忆一下:当时创建的索引及类型如下: {
"settings":{
"number_of_shards":3,
"number_of_replicas":1
"mappings":{
"community":{
"properties":{
"communityname":{
"type":"text"
"type":"keyword"
"type":"integer"
"creationdate":{
"type":"date",
"format":"yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
} 回过头来,我们现在插入一些文档进去。插入的ES的API:http://localhost:9200/rent/community/ 所有文档的插入请求体如下:你可以把这些数据插入到你的ES中,然后try后续的各种查询。 {
"communityname":"万科阳光苑",
"city":"上海",
"creationdate":" 00:00:00"
"communityname":"万科朗润园",
"city":"上海",
"creationdate":"2006...
以架构师的眼光来讲述高并发架构
专有网络VPC(Virtual Private Cloud)帮助您基于阿里云构建出一个隔离的网络环境。除了给您提供一个独立的虚拟化网络,阿里云还为每个VPC提供独立的路由器和交换机组件。您可以完全掌控自己的虚拟网络,包括私网IP地址范围、子网网段和路由配置等。 专有网络 专有网络是您基于阿里云创建的自定义私有网络, 不同的专有网络之间彻底逻辑隔离。您可以在自己的专有网络内创建和管理云产品实例,比如ECS,SLB和RDS。 在创建专有网络时,您需要以CIDR block的形式指定专有网络内使用的私网网段。关于CIDR block的相关信息,请参见维基百科上的Classless Inter-Domain Routing条目说明。 产品优势 阿里云的专有网络具有如下明显优势: 安全隔离 不同用户的云服务器部署在不同的专有网络里。 不同专有网络之间通过隧道ID进行隔离。专有网络内部由于交换机和路由器的存在,所以可以像传统网络环境一样划分子网,每一个子网内部的不同云服务器使用同一个交换机互联,不同子网间使用路由器互联。 不同专有网络之间内部网络完全隔离,只能通过对外映射的IP(弹性公网IP和NAT IP)互联。 由于使用隧道封装技术对云服务器的IP报文进行封装,所以云服务器的数据链路层(二层MAC地址)信息...
了解一下微信小程序开发,首先学习如何安装开发工具!
一.node特点 1.异步I/O 2.事件和回调函数 (事件的编程方式具有轻量级,松耦合,只关注事务点的优势) 3.单线程 (优点:不用处处在意状态同步问题,没有死锁,没有线程上下文交换的性能开销。 缺点:无法利用多核CPU,大量计算占用CPU,错误会引起整个应用退出,应用健壮性值得考虑。 node通过 child_process 解决单线程大计算量问题) 4.跨平台 (基于libuv实现)
应用场景 I/O密集型 分布式应用
时代的潮流浩浩荡荡,上升到国家发展战略与基础设施的人工智能,正以不可思议的速度占据着我们生活的头条。如果说2017年宣告了人工智能接棒时代脉搏,那么2018年的人工智能将作为颠覆性变革力量迭代世界机器的运作。
点开LinkedHashMap的源码 可以看到 继承HashMap&K,V& 实现Map接口 我们注意到 在源码开头描述中有一段话 都实现了Map接口 并且区别在于linkedHashMap是一个双端队列组成 可以看见比HashMap的Entry多了两个参数 before,after 也是使用的Hash'Map的Entry构造器 包括实例化LinkedHashMap的时候调用的也是父类(HashMap)的构造器,put方法,remove方法都是走的HashMap的方法 可以看到 LinkedHashMap的内存结构与HashMap是一样的 唯一区别就是他的链表
HashMap的Entry链表 只有一个next参数 相当于单向链表 而LinkedHashMap的链表有 after,before两个参数 相当于双向链表 可以看出 在做大量查找操作的时候
LinkedHashMap的效率要比HashMap的高 其他基本无区别 做增加操作基本等量 也就多了两个“指针”赋值 注意此处的指针 并不是真正的指针
使用Java内置的Http Server构建Web应用
底部选项卡tab有两种实现方式,一种是用js另一种是原生的 一、js实现方式:首先先建1个首页和几个子页,最后合并而成 &!DOCTYPE html&
&meta charset="utf-8"&
&meta name="viewport" content="width=device-width,initial-scale=1,minimum-scale=1,maximum-scale=1,user-scalable=no" /&
&title&&/title&
&!--ctrl+d删除空白行--&
&link href="css/mui.min.css" rel="stylesheet" /&
&!--.mui-bar-nav~.mui-content这两个class之间的~什么意思?匹配 .mui-bar-nav 之后所有的 .mui-content(即同级的其他类或元素)。--&
&header class="mui-bar mui-bar-nav"&
&h1 class="mui-title"&首页&/h1&
&div&content&/div&
&nav class="mui-bar mui-bar-tab"&
&a class="mui-tab-item mui-active" href="html/home.html"&
&span class="mui-icon mui-icon-home"&&/span&
&span class="mui-tab-label"&首页&/span&
&a class="mui-tab-item" href="html/message.html"&
&span class="mui-icon mui-icon-chatboxes"&&/span&
&span class="mui-...
如今是一个数据说话的时代,同时也是一个数据竞争的时代,一切都是靠数据说话,而也正是因为这样方方面面的原因,让数据分析师这个职业水涨船高,市场需求很大。那么,我们需要先了解一下什么是数据分析师。 数据分析师 是数据师的一种,指的是不同行业中,专门从事行业数据搜集、整理、分析,并依据数据做出行业研究、评估和预测的专业人员。 尤其是互联网时代,数据过剩,数据分析师必须学会借助技术手段进行高效的数据处理。更为重要的是,互联网时代的数据分析师要不断在数据研究的方法论方面进行创新和突破。那么一名合格的数据分析师需要具备什么样的技能呢? 理解数据库 如果你想成为一名数据分析师,你会发现几乎一切都是用数据库来存储数据,如MySQL,PostgreSQL,CouchDB,MongoDB,Cassandra等。理解数据库并且能熟练使用它,将是一个基础能力。 数据管理 数据管理与数据库的结构有关,这些数据库可以对谁有权访问不同的信息给予复杂的规定。尽可能有效地存储数据有许多的不同方法。 需要数据管理技能的常见工作是数据库管理员。 商业智能 商业智能是通过收集数据来影响业务决策的做法。 目前世界500强企业中,有90%以上都建立了数据分析部门。IBM、微软、Googl...
传统情况下在java代码里访问restful服务,一般使用Apache的HttpClient。不过此种方法使用起来太过繁琐。spring提供了一种简单便捷的模板类来进行操作,这就是RestTemplate。 使用restTemplate访问restful接口非常的简单粗暴无脑。(url, requestMap, ResponseBean.class)这三个参数分别代表 请求地址、请求参数、HTTP响应转换被转换成的对象类型。 RestTemplate方法的名称遵循命名约定,第一部分指出正在调用什么HTTP方法,第二部分指示返回的内容。本例中调用了restTemplate.postForObject方法,post指调用了HTTP的post方法,Object指将HTTP响应转换为您选择的对象类型。还有其他很多类似的方法,有兴趣的同学可以参考官方api。 下面写了一个简单案例: 创建一个Mavne的SpringBoot项目,可以参照文档创建项目:Spring Boot Hello World (使用Eclipse IDE) 创建RestTemplateConfig配置类 package org.
import org.springframework.context.annotation.B
import org.springframework.context.annotation.C
import org.springframework.http.client.ClientHttpRequestF
import org.springframework.http.client.SimpleClientHttpRequestFacto...
微信小程序之获取并解密用户数据(获取openid,nickName) 用户性别、所在城市、所在省份、所在国家、用户的语言
使用Mycat 做简单的读写分离
原本使用的是amoeba做的读写分离,但是amoeba早已经停止了维护,有问题也没有办法解决,并且不支持双主多重模式.最近mycat又非常火热.觉得用mycat替换现有的amoeba. 温馨提示: 配置mycat之前请做好准备工作,统一各个数据库的字符集.并且最好使用mysql5.6的版本进行配置.以免以为版本问题带来很多未知的麻烦! 一、下载mycat 安装
mycat的官网网址
http://www.mycat.org.cn/ 我使用的是mycat的1.6的Linux安装包
tar -zxvf Mycat-server-1.6-RELEASE-10-linux.tar.gz
#解压后放到/usr/local下
mv mycat /usr/local
二、配置环境变量 检查是否已经配置好了java的环境变量 如果你还没用配置好,需先配置.
三、修改mycat配置文件 接下来修改mycat的配置文件
/usr/local/mycat/conf 配置文件非常多,如果只是简单配置在不同的服务器上进行读写分离只需要配置两个文件 server.xml 和
schema.xml
(一)先配置server.xml 找到这一段 &/system&
&user name="test"&
1.点击idea中tomcat设置
2.点击deployment查看Deploy at the server startup 中tomcat每次所运行的包是 xxxx:war 还是其他,如果是xxxx:war包,请更换.点击旁边绿色加号,选择 xxxx:war exploded ,然后将 xxxx:war 点击红色删除掉 3.然后在server中 将 "On Update action"、"On frame deactivation" 都选择 update classes and resources 4.大功告成,已亲测,不用因为每次修改代码而重启了!
4月21日,阿里巴巴第七届UCAN用户体验设计论坛上,一系列重磅消息接连抛出:内部孵化两年后,阿里设计机器人鲁班更名为“鹿班”,并首度开始向外输送服务能力;同时,阿里还诞生了首款“懂感情”的视频生成机器人Aliwood。 热点热议 阿里AI新物种!设计机器人两年赶上资深员工水平 作者:技术小能手 阿里云ACE同城会上海4月7日活动回顾! 作者:小可同学 区块链上的中国?2018见分晓 作者:雪花又一年 知识整理 为 Node.js 应用建立一个更安全的沙箱环境 作者:houfeng Java基本理论及编程语言分类4.23 作者:ludan60 SpringBoot+Docker+Git+Jenkins实现简易的持续集成和持续部署 作者:whs0668 Linux网络管理及配置IP及磁盘管理 作者:ludan60 Swift的类,及存储属性,计算发发样码 作者:天飞 美文回顾 以中国数字技术,驱动“数字中国” 作者:阿里云头条 区块链商业平台使用人工智能简化网上购物 作者:北丐09 物联网遇上区块链,将面临哪些机遇和挑战? 作者:北丐09 IBM 取得内存计算新突破,AI 训练能耗降低 80 倍 作者:技术小能手 区块链应用 | 将区块链技术映射到实体经济?「ValueCyber」想成为下一代区块链底层 作者:雪花又一年 对话清华经管朱恒源:中国智...
4G时代为移动网络性能带来的极大的提升,通过网络进行音频视频通话更加方便。在iOS系统中,可以配合使用VOIP与CallKit框架进行创建体验优质的通讯效果。本篇博客主要介绍iOS系统中,VOIP与CallKit的应用。
转自 https://blog.csdn.net/xiaoxiangzi222/article/details/
http://robinzheng.com//%E9%80%BB%E8%BE%91%E5%9B%9E%E5%BD%92%E4%B8%8E%E8%AE%A1%E7%AE%97%E4%B8%AD%E7%9A%84%E5%90%91%E9%87%8F%E5%8C%96%E6%80%9D%E6%83%B3/ http://xuhongxu.com/ml7-logistic-regre-grad-desc/
插件地址: 链接:https://pan.baidu.com/s/1E9OFzTck-TzW1pE59_KDGQ 密码:hxxz 1、打开Chrome浏览器,找到“工具 -& 扩展程序”; 2、将下载的Axure-RP-Extension-for-Chrome-0.6.2.crx文件拖到界面当中; 3、安装成功后,勾选“允许访问文件网址”就可以了。 重启Chrome
Springboot给我们提供了两种“开机启动”某些方法的方式:ApplicationRunner和CommandLineRunner。 这两种方法提供的目的是为了满足,在项目启动的时候立刻执行某些方法。我们可以通过实现ApplicationRunner和CommandLineRunner,来实现,他们都是在SpringApplication 执行之后开始执行的。 CommandLineRunner接口可以用来接收字符串数组的命令行参数,ApplicationRunner 是使用ApplicationArguments 用来接收参数的 他们的执行时机为容器启动完成的时候。 代码示例: @Component//被spring容器管理
@Order(1)//如果多个自定义ApplicationRunner,用来标明执行顺序
public class MyApplicationRunner implements ApplicationRunner {
public void run(ApplicationArguments applicationArguments) throws Exception {
System.out.println("--------------&" + "项目启动,now=" + new Date());
myTimer();
public static void myTimer(){
Timer timer = new Timer();
timer.schedule(new TimerTask() {
public void run() {
System.out.println("------...
Struts2的标签库 简介
Struts2的标签库使用OGNL为基础,大大简化了数据的输出,也提供了大量标签来生成页面效果,功能非常强大。
在早期的web应用开发中,jsp页面主要使用jsp脚本来控制输出。jsp页面嵌套大量的java脚本。
导致页面的可读性较差,可维护性也很低,页面美工人员不懂java,java开发人员也不懂美工设计。
JSP规范1.1之后,增加了自定义标签库的规范。
通过使用自定义标签库,在简单的标签中封装复杂的功能,从而避免了jsp页面中出现大量java代码。
JSP规范制订了一个标准的标签库,JSTL。
Struts2的标签库的标签不依赖于任何表现层技术,也就是说,Struts2提供的标签,可以在各种表现层技术中使用,包括jsp页面。
Struts2的标签主要分为三类
-UI标签:主要用于生成HTML元素的标签
-非UI标签:主要用于数据访问,逻辑控制等
-Ajax标签:用于Ajax支持的标签
OGNL表达式
Struts2利用内建的OGNL表达式语言支持,大大增加了Struts2的数据访问功能,Xwork在原有的OGNL的基础上,增加了对ValueStack的支持。
我们每次发出请求时,都会产生请求数据,这些数据存放在哪里呢?
许多个人和组织认为,BCH是加密货币领域的有力竞争者,过去的9个月只是一个开始,在今年,BCH将有希望实现巨大突破。前几天,比特币矿池Antpool也有类似的说法:“比特币现金区块链正处于成为一个被广泛使用的公共区块链的临界点。“ 交易所和钱包供应商的支持 自8月1日以来,BCH诞生接近9个月了,已经从钱包供应商和交易所那里得到了大量的支持。在这么短的时间内,没有其他的加密货币能在如此短的时间内获得如此多的支持。支持BCH的交易所包括:Bitstamp,Coinbase、Kraken、Bithumb、GDAX、Binance、Poloniex、Bittrex等。比特币现金也有很多知名的钱包供应商支持,包括Edge、Bread、Jaxx、Copay、Exodus、Ledger、Trezo、Stash、Mobi等。此外,BCH有6个完整的节点支持,包括Bitcoin ABC, Unlimited, XT, Parity, Flowee和 Bitprim,这些团队和区块链公司一起为BCH提供了开放性的开发环境。
BCH的商业接受度与BCE之外的其他加密货币相比也是有差别的,由于Bitpay的支持,现在成千上万的商家可以接受比特币现金支付,包括微软和新加坡的一些知名公司,再加上例如Openbazaar这样的项目,利用钱包支持的方式,比特币现金将涵盖几乎所有原本BCE的基础设施。 一个充...
# jvm - 垃圾回收 注意 : 本系列文章为学习系列,部分内容会取自相关书籍或者网络资源,在文章中间和末尾处会有标注 ## **垃圾回收的意义** 它使得java程序员不再时时刻刻的关注内存管理方面的工作. 垃圾回收机制会自动的管理jvm内存空间,将那些已经不会被使用到了的"垃圾对象"清理掉",释放出更多的空间给其他对象使用. ## **何为对象的引用?** Java中的垃圾回收一般是在Java堆中进行,因为堆中几乎存放了Java中所有的对象实例 在java中,对引用的概念简述如下(引用强度依次减弱) : - **强引用** : 这类引用是Java程序中最普遍的,只要强引用还存在,垃圾收集器就永远不会回收掉被引用的对象 - **软引用** : 用来描述一些非必须的对象,在系统内存不够使用时,这类对象会被垃圾收集器回收,JDK提供了SoftReference类来实现软引用 - **弱引用** : 用来描述一些非必须的对象,只要发生GC,无论但是内存是否够用,这类对象就会被垃圾收集器回收,JDK提供了WeakReference类来实现弱引用 - **虚引用** : 与其他几种引用不同,它不影响对象的生命周期,如果这个对象是虚运用,则就跟没有引用一样,在任何时刻都可能会回收,JDK提供了PhantomReference类来实现虚引用 **如下为相关示例代码** ```j...
自从微服务概念以来,众多的软件架构在践行着这一优秀的设计理念。各自的系统在这一指导思想下收获了优雅的可维护性,但一方面也给接口调用提出了新的要求。比如众多的API调用急需一个统一的入口来支持客户端的调用。在这种情况下API GATEWAY诞生,我们将接入、路由、限流等功能统一由网关负责,各自的服务提供方专注于业务逻辑的实现,从而给客户端调用提供了一个稳健的服务调用环境。之后,我们在网关大调用量的情况下,还要保证网关的可降级、可限流、可隔离等等一系列容错能力。 一、网关 这里说的网关是指API网关,直面意思是将所有API调用统一接入到API网关层,有网关层统一接入和输出。一个网关的基本功能有:统一接入、安全防护、协议适配、流量管控、长短链接支持、容错能力。有了网关之后,各个API服务提供团队可以专注于自己的的业务逻辑处理,而API网关更专注于安全、流量、路由等问题。 1.1、单体应用 单体应用.png
业务简单,团队组织很小的时候,我们常常把功能都集中于一个应用中,统一部署,统一测试,玩的不易乐乎。但随着业务迅速发展,组织成员日益增多。我们再将所有的功能集中到一个TOMCAT中去,每当更新一个功能模块的时候,势必要更新所有的程序...
时代的潮流浩浩荡荡,上升到国家发展战略与基础设施的人工智能,正以不可思议的速度占据着我们生活的头条。如果说2017年宣告了人工智能接棒时代脉搏,那么2018年的人工智能将作为颠覆性变革力量迭代世界机器的运作。
## 写在前面 因为对Vue.js很感兴趣,而且平时工作的技术栈也是Vue.js,这几个月花了些时间研究学习了一下Vue.js源码,并做了总结与输出。 文章的原地址:[https://github.com/answershuto/learnVue](https://github.com/answershuto/learnVue)。 在学习过程中,为Vue加上了中文的注释[https://github.com/answershuto/learnVue/tree/master/vue-src](https://github.com/answershuto/learnVue/tree/master/vue-src)以及Vuex的注释[https://github.com/answershuto/learnVue/tree/master/vuex-src](https://github.com/answershuto/learnVue/tree/master/vuex-src),希望可以对其他想学习源码的小伙伴有所帮助。 可能会有理解存在偏差的地方,欢迎提issue指出,共同学习,共同进步。 ## Vuex 我们在使用Vue.js开发复杂的应用时,经常会遇到多个组件共享同一个状态,亦或是多个组件会去更新同一个状态,在应用代码量较少的时候,我们可以组件间通信去维护修改数据,或者是通过事件总线来进行数据的传递以及修改。但是当应用逐渐庞大以后,代码就会变得难以维护,从父组件开始通过prop传递多层嵌套的数据由于层级过深而显得异常脆弱,而事件总线也会因为组件的增多、代码量的增...
本文介绍ActiveMQ在SpringBoot中的使用,其中配置都基于注解
业务系统中,通常会遇到这些场景:A系统向B系统主动推送一个处理请求;A系统向B系统发送一个业务处理请求,因为某些原因(断电、宕机。。),B业务系统挂机了,A系统发起的请求处理失败;前端应用并发量过大,部分请求丢失或后端业务系统卡死。。。。这个时候,消息中间件就派上用场了--提升系统稳定性、可用性、可扩展性。 一、消息中间件 消息队列技术是分布式应用间交换信息的一种技术。消息队列可驻留在内存或磁盘上,队列存储消息直到它们被应用程序读走。通过消息队列,应用程序可独立地执行--它们不需要知道彼此的位置、或在继续执行前不需要等待接收程序接收此消息。 总体来说,消息中间件有以下作用:降低耦合、流量消峰(防浪涌)、可靠性传输、事件驱动 1.降低耦合:通过发布订阅的方式松耦合 我们以注册业务为例,注册成功会发送短信、邮件给用户来确认,传统架构模型是这样: 邮件业务和短信业务的代码是写在用户注册的流程里,无论是通过接口的方式来实现,还是远程调用的方式来实现,耦合度都很高,现在,新增一个需求,用户注册完成以后不发送邮件了,而是给用户“增加积分”,我们来分析这几种情况: 第一、都在一个业务系统内通过代码堆积、接口调用的方式来...
1行代码实现人脸识别,1. 首先你需要提供一个文件夹,里面是所有你希望系统认识的人的图片。其中每个人一张图片,图片以人的名字命名。2. 接下来,你需要准备另一个文件夹,里面是你要识别的图片。3. 然后你就可以运行face_recognition命令了,把刚刚准备的两个文件夹作为参数传入,命令就会返回需要识别的图片中都出现了谁,1行代码足以!!!
发现很多Kubernetes刚入门的同学对Kubernetes的Master高可用方案很感兴趣,官方又只给出了GCE上部署高可用的方案,因此我觉得有必要把我之前做的Kubernetes Master HA方案分享一下。
JVM性能调优涉及到方方面面的取舍,往往是牵一发而动全身,需要全盘考虑各方面的影响,那么如何进行一次优雅的调优,提升应用的性能?
本文讲述了如何使用Jenkins来对项目持续集成,分别以Java和C#两类常见的项目类型做了演示。由于时间关系,仅仅简单讲述了如何配置和创建基本的持续集成项目。其实利用Jenkins除了上面演示的功能之外,还可以在构建完成后将失败或者成功的消息发邮件通知到相关人员,甚至自动部署到服务器(一般是部署到测试环境供QA测试,直接发布到正式服务器还是要慎重一点)。
标题是我以第一视角基于 Electron 开发客户端产品的体验,我将在之后分一系列文章向有兴趣的朋友一步一步介绍我是怎么从玩玩具的心态开始接触 Electron 到去开发客户端产品,最后随着业务和功能的复杂度提升再不断地优化客户端。
1、Eureka Server 提供服务注册服务,各个节点启动后,会在Eureka Server中进行注册,这样Eureka Server中的服务注册表中将会存储所有可用服务节点的信息,服务节点的信息可以在界面中直观的看到。 2、Eureka Client 是一个Java 客户端,用于简化与Eureka Server的交互,客户端同时也具备一个内置的、使用轮询负载算法的负载均衡器。 3、在应用启动后,将会向Eureka Server发送心跳(默认周期为30秒),如果Eureka Server在多个心跳周期没有收到某个节点的心跳,Eureka Server 将会从服务注册表中把这个服务节点移除(
最近在项目中研究计步模块,主要功能记录当天步数,类似微信运动,支付宝计步,咕咚今日步数。 [本篇文章简书地址](http://www.jianshu.com/p/cfc2a200e46d)
[国内首家]以太坊区块链实战教学:http://edu.csdn.net/course/detail/6455 LinApex个人简介
奋斗在区块链网络在数字货币交易平台,底层框架设计,区块链钱包,区块链解决方案一线,做过人工智能,金融支付行业,目前正在做一款区块链+黄金的App系统。 玩赚区块链QQ群:
连载系列(基于以太坊)
1、【区块链】以太坊区块链技术初探
2、【区块链】以太坊区块链环境搭建
3、【区块链】以太坊区块链概念了解
4、【区块链】以太坊区块链技术进阶
1、【以太坊源码】编译以太坊源码,打造自己的公链私链
2、【以太坊源码】以太坊源码研究系列(以太坊模拟机、挖矿、点对点网络库、节点发现、合约代码传输、加密签名等)
区块链基本概念
区块链就是通过密码学的方式形成的一个由集体维护的分布式数据库。
区块链的概念最近很火,它来自于比特币等加密货币的实现,但是目前,这项技术已经逐步运用在各个领域。什么是区块链技术?为了感性认识这个问题,我们可以使用谷歌地球的例子做类比,ajax不是什么新技术,但组合在...
项目部署线上之后,我们该如何基于监控工具来快速定位问题....
开源地址:https://github.com/bluejoe2008/openwebflow(欢迎star) 1.
OpenWebFlow概述 OpenWebFlow是基于Activiti扩展的工作流引擎。Activiti (官方网站http://activiti.org/,代码托管在https://github.com/Activiti/Activiti)是一个新兴的基于 Apache 许可的支持 BPMN 2.0 标准的开源 BPM 产品,它是一个轻量级,可嵌入的 BPM 引擎,并且提供了功能丰富的开发和流程设计工具。OpenWebFlow与业务应用系统之间的关系如下图所示。 相对于Activiti,OpenWebFlow扩展的功能包括: 1) 完全接管了Activiti对活动(activity)权限的管理。 Activiti允许在设计model的时候指定每个活动的执行权限,但是,业务系统可能需要根据实际情况动态设置这些任务的执行权限(如:动态的Group)。OpenWebFlow完全实现了与流程定义时期的解耦,即用户对活动的访问控制信息单独管理(而不是在流程定义中预先写死),这样有利于动态调整权限,详见自定义活动权限管理; 2) 完全接管了Activiti对用户表(IDENTITY_XXX表)的管理。 在标准的工作流定义中,每个节点可以指定其候选人和候选用户组,但是比较惨的是,Activiti绑架了用户信息表的设计!这个是真正致命的,因为几乎每个业务...
本文节选自《疯狂工作流讲义(第2版)》 京东购买地址:https://item.jd.com/.html 疯狂Activiti电子书:https://my.oschina.net/JavaLaw/blog/1570397 工作流Activiti教学视频:https://my.oschina.net/JavaLaw/blog/ 流程控制逻辑
本小节将以一个简单的例子,讲述Activiti关于流程处理的逻辑。 11.1 概述
在Activiti5以及jBPM4,对流程的控制使用的是流程虚拟机这套API,英文为Process Virtual Machine,简称PVM。PVM将流程中的各种元素抽象出来,形成了一套Java API。
新发布的Activiti6.0版本中,PVM及相关的API已经被移除,取而代之的是一套全新的逻辑,本小节将以一个例子,讲述这套全新逻辑,是如何进行流程控制的,本小节的案例,目的是为了让读者了解新版本Activiti是如何进行流程控制的。 11.2 设计流程对象
基于BPMN规范,Activiti创建了对应的模型,由于BPMN规范过于庞杂,为了简单起见,在本例中,我们也先创建自己的规范。代码清单18-1为一份定义我们自己流程的XML文档。
代码清单18-1:codes\18\18.1\my-bpmn\resource\myBpmn.xml &?xml version="1.0"...
SpringMVC相信大家已经不再陌生了,大家可能对于Spring的各种XML配置已经产生了厌恶的感觉,Spring官方发布的Springboot 已经很长时间了,Springboot是一款“约定优于配置”的轻量级框架;Springboot首先解决的就是各种繁琐的XML配置,你可以不用任何XML配置,进行web服务的搭建,其次是Springboot本身就继承了web服务器,如果说前端开发人员想在本地启动后端服务不需要进行各种配置,几乎可以做到一键启动。 再有就是目前大热的微服务,而Springboot恰恰满足了快速开发微服务的开发场景;对于目前主流的框架Spring+MyBatis+redis的集成,好吧直接看代码... 以下代码是整个开发框架集成完之后的,关于Spring官方那一套如何编写启动类,如何配置端口这些随便google一大把的我就不再本文说明了。下面的代码,mybatis mapper我就不贴了,平常怎么写现在也一样,还有redis存数据取数据什么的。本文给的都是划的重点啊! 1.数据源以及其他的配置文件(PS:说好了不配置,怎么刚开始就上配置? 答:不配置也可以,如果你想把数据源硬编码写死的话。^_^) 下面给的是YML的配置文件方式,YML被各种主流的开发语言所支持,相当于常见的.properties文件。 jedis :
定时任务不须多言,几乎是每个项目必备功能,而原生的quartz用起来着实有点哆嗦,市面上也有不少依赖spring的定时任务组件,因为笔者本人已经完全抛弃spring(笔者还抛弃了servlet),所以自己动手对quartz进行了简单封装,使其更容易开发和维护! 引入相关jar &dependency&
&groupId&org.quartz-scheduler&/groupId&
&artifactId&quartz&/artifactId&
&version&2.3.0&/version&
&/dependency&
&dependency&
&groupId&org.quartz-scheduler&/groupId&
&artifactId&quartz-jobs&/artifactId&
&version&2.3.0&/version&
&/dependency&
&dependency&
&groupId&org.t-io&/groupId&
&artifactId&tio-core&/artifactId&
&version&2.0.1.v-RELEASE&/version&
&/dependency&
创建任务类 import org.quartz.J
import org.quartz.JobExecutionC
import org.quartz.JobExecutionE
* @author tanyaowu
* 日 下午4:58:34
public class ZzzJob implements Job {
public ZzzJob() {
* @param context
* @throws JobExecutionException
* @author: tanyaowu
public void execute(Jo...
一张精彩的导图
关注公众号回复“正则导图”即可下载xmind源文件
导图内容解析 语法结构 字符 普通字符:字母、数字、汉字、下划线,匹配与之相同的一个字符 简单转义字符:\n(换行),\t(制表),\\(\本身)和 \^...(\^等有特殊作用的符号如要匹配自己的话要用转义) 标准字符集合 注意区分大小写,大写是相反的意思,匹配相反是不匹配 \d 任意一个数字,0~9 \w 任意一个字母、数字、汉字或下划线,A~Z、a~z、0~9、_和任意一个汉字 \s 任意空白符,包括空格、制表符、换行符 . 小数点可以匹配任意一个字符,换行除外(如果要匹配包括"\n"在内的所有字符,一般用[\s\S]) 自定义字符集合 [ ]方括号匹配方式,能够匹配方括号中的任意一个字符,^表示取反 [ab5@] 匹配"a"或"b"或"5"或"@" [^abc] 匹配a、b、c之外的任意字符 [f-k] 匹配“f"到"k"之间的字符 [^A-F0-3] 匹配“A"-"F","0"-"3"之外的任意一个字符 量词(Quantifier) 修饰前面的一个表达式,如果要修饰多个表达式,就用( )把表达式包起来 {n} 表达式重复n次 {m,n} 表达式至少重复m次,最多重复n次 贪婪模式 (默认) 匹配符合的最长的字符串 非贪婪模式 (在量词后面加 ? 例:{m,n}? ) 匹配符合的最短的字符...
## 指令 - 解释:指令 (Directives) 是带有 `v-` 前缀的特殊属性 - 作用:当表达式的值改变时,将其产生的连带影响,响应式地作用于 DOM ### 常用指令 - v-text - v-html - v-bind ### v-text - 解释:更新元素的 textContent ``` ``` ### v-html - 解释:更新元素的 innerHTML ``` ``` ### v-bind - 作用:当表达式的值改变时,将其产生的连带影响,响应式地作用于 DOM - 语法:`v-bind:title="msg"` - 简写:`:title="msg"` ``` ``` ### v-on - 作用:绑定事件 - 语法:`v-on:click="say"` or `v-on:click="say('参数', $event)"` - 简写:`@click="say"` - 说明:绑定的事件从`methods`中获取 ``` ``` ### 事件修饰符 - `.stop` 阻止冒泡,调用 event.stopPropagation() - `.prevent` 阻止默认事件,调用 event.preventDefault() - `.capture` 添加事件侦听器时使用事件`捕获`模式 - `.self` 只当事件在该元素本身(比如不是子元素)触发时触发回调 - `.once` 事件只触发一次 ### v-model - 作用:在表单元素上创建双向数据绑定 - 说明:监听用户的输入事件以更新数据 ``` Message is: {{ message }} ``` ### v-for - 作用:基于源数据多次渲染元素或模板块 ``` {{ ite...

